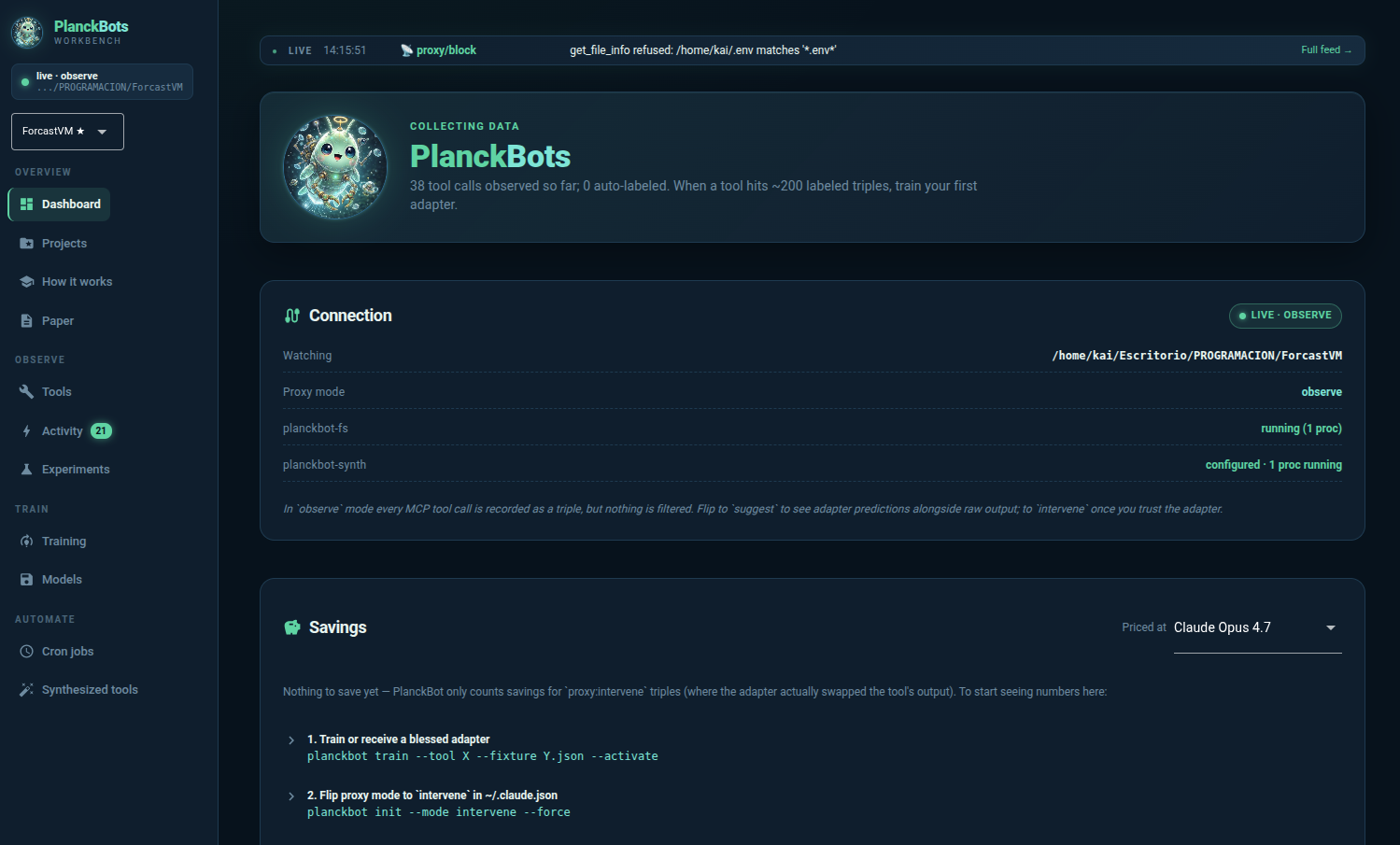
Observe
Every MCP tool call gets logged as a triple (input, raw output, what the host LLM quoted in its next turn). No interference, no swapping. Just data.
 PlanckBots
PlanckBots
Adaptive tiny-model layer · Apache 2.0
PlanckBot sits between a host LLM and its tools. Observes every call, trains a per-tool LoRA on what the model actually quotes in its next turn, then silently compresses the noisy parts at runtime.
list_directory
Each layer is a separate switch you can flip on its own. Start at A, keep adding as you trust the data.
Every MCP tool call gets logged as a triple (input, raw output, what the host LLM quoted in its next turn). No interference, no swapping. Just data.
A per-tool LoRA (SmolLM2-135M base) is trained on those triples. At inference, the proxy swaps raw→filtered when the adapter's confidence clears threshold. Claude doesn't know.
The host LLM can propose source-level edits to tool code through a meta-tool that's AST-whitelisted. Every edit bumps the tool's version and invalidates the adapter trained against the old one.
A pattern detector watches for repeating tool sequences and proposes merged synthesized tools. AST-gated generation, hot-reloaded through a second MCP server.
git clone https://github.com/opcastil11/planckbot && cd planckbot
uv venv .venv && source .venv/bin/activate
uv pip install -e ".[dev]"
# First-run setup: creates data dir, migrates DB, registers MCP with Claude Code
planckbot init --upstream-path /path/to/your/project --claude-config
# Launch the workbench
planckbot ui # http://localhost:8080
Restart Claude Code in that folder. Every filesystem call becomes a triple. After ~200 calls per tool, train the first adapter with planckbot train --tool X --fixture Y.json.
Proxy-level secret filtering. Blocks .env, SSH keys, cloud creds before they ever reach the LLM — regardless of what you explicitly tell Claude not to read.
SQLite-backed event bus. Every proxy interception, cron run, synth lifecycle, training event streams into a 500 ms-polled log you can watch.
Switch which folder Claude Code is watching without losing the triples and adapters from the previous one.
Adapters don't serve in production until a human explicitly blesses them. Unbless = one command revert when an adapter regresses.
Off / Soft / Hard per project. Soft nudges Claude via CLAUDE.md; Hard denies native Read/Glob/Grep so everything flows through the MCP.
Built-in job types (autolabel, retrain signal, conversation scanner, gap detection). systemd user unit included.